
Git in practice
I think there are two important sets of things to learn when it comes to using git in practice. The first set is just the essential commands: How do you actually create a new “version” of your whatever your project is? How do you go back and forth between versions or compare differences between them? How do you synchronize your changes with collaborators? In the first subsection below I’ll quickly cover the basics, but again: there are many other resources for learning these basics!
The second set is a byproduct of (a) git’s “branching” model of projects and (b) the fact that git is a distributed version control system. “Distributed” here means that no copy of the project is more or less important than any other, except by convention. This has several nice features, but it also means there are many different patterns for interacting with git and using it for version control. Especially when collaborating — but even when just working on your own code base — it is helpful to choose a consistent pattern of using git. These patterns are usually called “workflows.” While there are many different possible workflows, I think there are two that are most useful for solo projects or those involving only a small number of collaborators at a given time. I’ll describe these two after covering the core commands.
The core commands
Nobody likes to be told to read the documentation, but the first command to know about is running git help [command] from the shell, where “[command]” is, not surprisingly, any git command. It will remind you what the command does, what its options are, and other helpful pieces of information. Since this guide is, after all, for people who want to learn git later, it’s good to know the first place to start with that!
Getting started: init and clone
A repository (“repo”) is git’s fundamental unit — each project (a paper, a codebase, a website, etc) will live in its own repo. That repo will contain all of the files associated with that project, each file’s complete version history, and can even contain various parallel or alternate versions of files. You can create a new repository by moving to some directory and running git init — this initializes a repo by creating and populating a hidden .git/ subdirectory. You can also use git clone [repository], where [repository] is a path to a local repo or a URL pointing at a remote one, to create a new copy of an existing repo.
Creating versions of your project: status, diff, add, commit
Git has a “stage-and-commit” model for updating repositories. It might be useful to think of commits as the actual versions of the project you’ll be able to go back and forth between, and the “staging area” as a rough draft space for the version you are about to commit. One reason for having this distinction is that some workflows favor having small commits that each address some specific update to the project, and using git’s stage-and-commit model let’s you take the many changes you may have made during a coding session and record them as a specific sequence of project versions.
In practice, you can see the current status of your project by running the well-named git status command. This will give an overview of your project relative to the last version that was committed: what files are in the staging area ready to be committed, and what files have been changed (or what new files have been added) but are not in the staging area. If you want more granular detail here — for instance, what lines of various files have actually been changed — you can use the git diff command.
To actually move a file to the staging area you use the git add [filename] command, and to turn changes in the staging area into a new version of your project you use the git commit command. By default, running git commit will open up a text editor asking you to specify a “commit message” — this should be a short description of the changes associated with the new version of your project.
There are, of course, options for all of these git commands that make them easier to work with. For instance, if you want to add all new and changed files to the staging area you can use git add . If you want to skip the “let’s open up a text editor for the commit message” business you can use a -m flag on git commit. And if you want to skip the whole “staging area” stuff and just commit all changes to existing files, you can use a -a flag on git commit.
So, for instance, after I finish writing this section I’ll probably go to the shell and do something like:
$ git commit -am "added core git commands to git markdown file"
Moving between versions: log and checkout
After you have committed several versions of your project to the repo, you can use the git log command to view the history of your project. By default it will list commits in reverse chronological order, with four pieces of information for each commit: (1) a SHA-1 checksum that serves as the commit’s identifier, (2) the author of the commit, (3) the date of the commit, and (4) the commit message. There are many options to make the log easier to parse, and if you work with git a lot on the command line you’ll probably end up making a command line alias that does something like
$ git log --graph --abbrev-commit --decorate --format=format:'%C(bold blue)%h%C(reset) - %C(bold green)(%ar)%C(reset) %C(white)%s%C(reset) %C(dim white)- %an%C(reset)%C(bold yellow)%d%C(reset)' --all
to make viewing the commit history easier. Also, unless you’re very good at memorizing hashes, write useful messages.

Having the complete history of your project would be of only limited use if you couldn’t actually access past versions of your project, and git checkout is the basic command to get this job done. It is most commonly used for moving between different branches of your project (more on that below), but you can also use it to look at any commit in your repo: git checkout [commitID], where you replace [commitID] with the SHA hash of the commit you are interested in. Doing so will change the contents of your working directory to match what it was at that time. You can also do more fine-grained operations, such as checking out a specific file from a specific commit (git checkout [commitID] [path/to/file]), or discarding changes to a file in your working directory by checking out the version of that file from the most recent commit (git checkout -- [path/to/file]). I find that last operation quite useful. You’ll also notice that when you use the git status command, git gives you useful hints about things you might want to do, which often involves the checkout command.
Synchronizing clones: remote, push, pull
Even just using git locally for version control is very useful, but when collaborating you will almost always want to synchronize with a remote repo. Remotes are just versions of your repository that live somewhere on the internet (e.g., on GitHub, or GitLab, or…). If you started a repo with git init you can connect it to a remote repository using the git remote [various options] command (and if you cloned an existing remote your repo will be configured to synchronize easily with that remote by default). If you want you can associate arbitrarily many different remotes with your repository — this just involves many uses of the git remote command, and you can use git remote -v to see what your remotes are and how they are configured (read only, read-write).
Most of the time, you’ll probably keep things simple and only have a single remote associated with your project. In this case, once you’ve set the remote up synchronizing with it is quite straightforward. To move your local commits to the remote you git push, and to take any updates that the remote has and combine it with what you have locally you git pull. If you want to grab all of the data the remote has but you do not want to immediately try to combine it with what you have (perhaps you’re worried about incompatible changes you and a collaborator may have made to a file, and want to check everything out first), you can instead do a git fetch.
Creating parallel versions: branch and merge
Finally (for now!), git’s branching model makes it easy to have multiple parallel versions of your project that can develop independently from each other. This means you can (at no real cost!) create a new branch to experiment with some new feature (or develop it over a long time) without interfering with whatever is going on with the main part of your project. Creating a new branch is as simple as git branch [nameOfYourNewBranch], and switching between branches is as simple as git checkout [nameOfBranchYouWantToCheckout]. Each branch can independently maintain its own version history (see more on that below), and when synchronizing with a remote you have complete control – you can push and pull all of your branches, only some of them, or only have the main branch synchronized with your remote.
Eventually, you will decide that the feature you developed on some branch should be combined with your main branch (for the purposes of this guide, I’ll assume that your main branch is named main — the actual name makes no difference to git). The basic way of doing this is to use a “merge” command: assuming that you are currently on main (i.e., you’ve recently done a git checkout main) and you want to combine the work you did on a featureBranch1, you can just do
$ git merge featureBranch1
This will attempt to replay all of the changes made on featureBranch1 on top of main. If there is a conflict that cannot be automatically resolved — perhaps incompatible changes were made to the same file on these two branches — the merge will stop, and you will have options for how to resolve these conflicts. I strongly recommend not beginning a merge if you have any uncommitted changes in your project.
Odds and ends: configuring git
These aren’t commands per se, but there are two most useful ways of configuring how git works that are worth knowing about right out of the gate.
The first is your global .gitconfig file, which lives in your home directory (not your project directory), and can be created by hand or using the git config command. This needs to be used to set the name and email that will be associated with your commits, but can also be used to set lots of options — alias for commands you want git to use, the default editor to use when writing commit messages when not using the -m flag, and so on.
The second is the possibility to have both a global and a per-project .gitignore file. This is a file that tells git to not (by default — this can be overridden if you really want) incorporate certain files or types of files into your repo. Perhaps you like typing git add ., but you don’t want git to actually add anything in the build/ directory of your code base. This can be done by having a file named .gitignore in the root directory of your project, and then having a build/* line in it. Or perhaps you have a git repo for a paper you’re writing in LaTeX, but you don’t want to version control all of the extra files that get generated during the build phase. You could have a .gitignore with lines like
## LaTeX-related ignores
*.log
*.fls
*.out
*.aux
*.bbl
*.blg
*.synctex
*.synctex.gz
Fantastic.
Common workflows
These sections will be shorter, describing two basic patterns of interacting with git.
Centralized workflow
The first is usually called the “centralized workflow,” in which we ignore git’s branching model altogether and have all of our project’s history linearly recorded on the repo’s main (i.e., only) branch. Schematically, our project’s history will look like this:
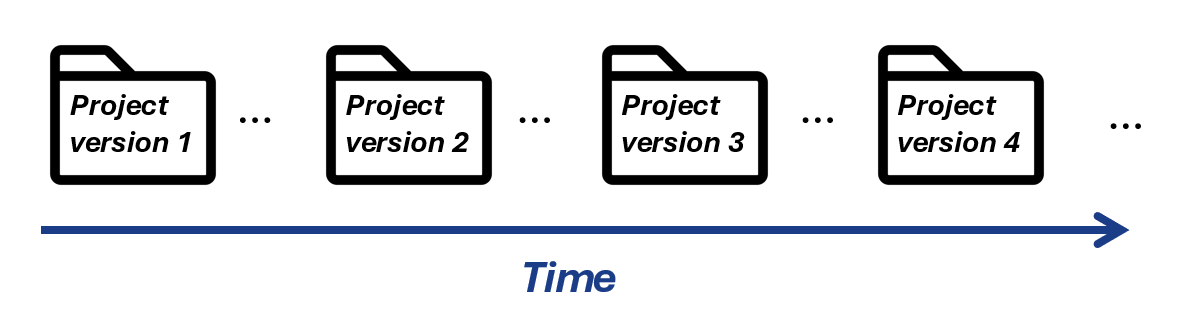
Schematic view of a project with a centralized workflow
In this schematic time progresses from left to right, and I’ve deliberately used dots to connect the project versions themselves rather than the arrows you might have expected. The reason for this choice will be clear when we talk about how git stores a repository, and we realize that arrows connecting the different versions should be drawn opposite to the flow of time.
This workflow works well for small computational projects — perhaps small analysis scripts, or collections of related mathematica / python notebooks — and also especially for working on papers (which should definitely be version-controlled with a method better than saving files with names like manuscriptDraft_v10_final_revision_v2.tex). The basic pattern of operation with this workflow is
- Initialize the repo:
git initorgit clone - Make and commit changes:
git status,git add, andgit commit - Synchronize with the remote
- Get any changes (if you are collaborating):
git pull- Handle any conflicts, if necessary
- Push changes:
git push
- Get any changes (if you are collaborating):
- Repeat steps 2 and 3 until done.
This simple pattern uses only a handful of git commands, but is already very useful. It can also be usefully thought of as a building block for more complicated ways of working with a repo. The next example demonstrates this, where I’ll use the abbreviation CWF to refer to steps 2–4 above.
Feature branch workflow
As projects get larger, the main branch of your project using CWF can start to get cluttered and chaotic. Perhaps you’re building a particle-based simulation framework, and you are simultaneously adding new forces and equations of motion and boundary conditions, all while occasionally finding and fixing a bug or two. The commits for these additions are all interwoven in your project’s history — does a particular new feature rely on a bug fix earlier in the commit history, or not? Are the changes you needed to make to a file containing a common simulationFramework class when working on two different features compatible, incompatible, or completely independent from each other?
A nice pattern for encapsulating the work on (relatively, if not completely) separate parts of your project is called a "feature branch workflow. " It is based around having a primary main branch for your project, and instead of committing directly to it you are encouraged to create a new branch when you want to start working on a new feature. These feature branches get merged with the main branch when they are ready, and then they don’t need to be touched again (below we’ll learn that branches are really not copies of data, so there is no cost to having a bunch of unused (“stale”) branches around). It looks schematically like so:
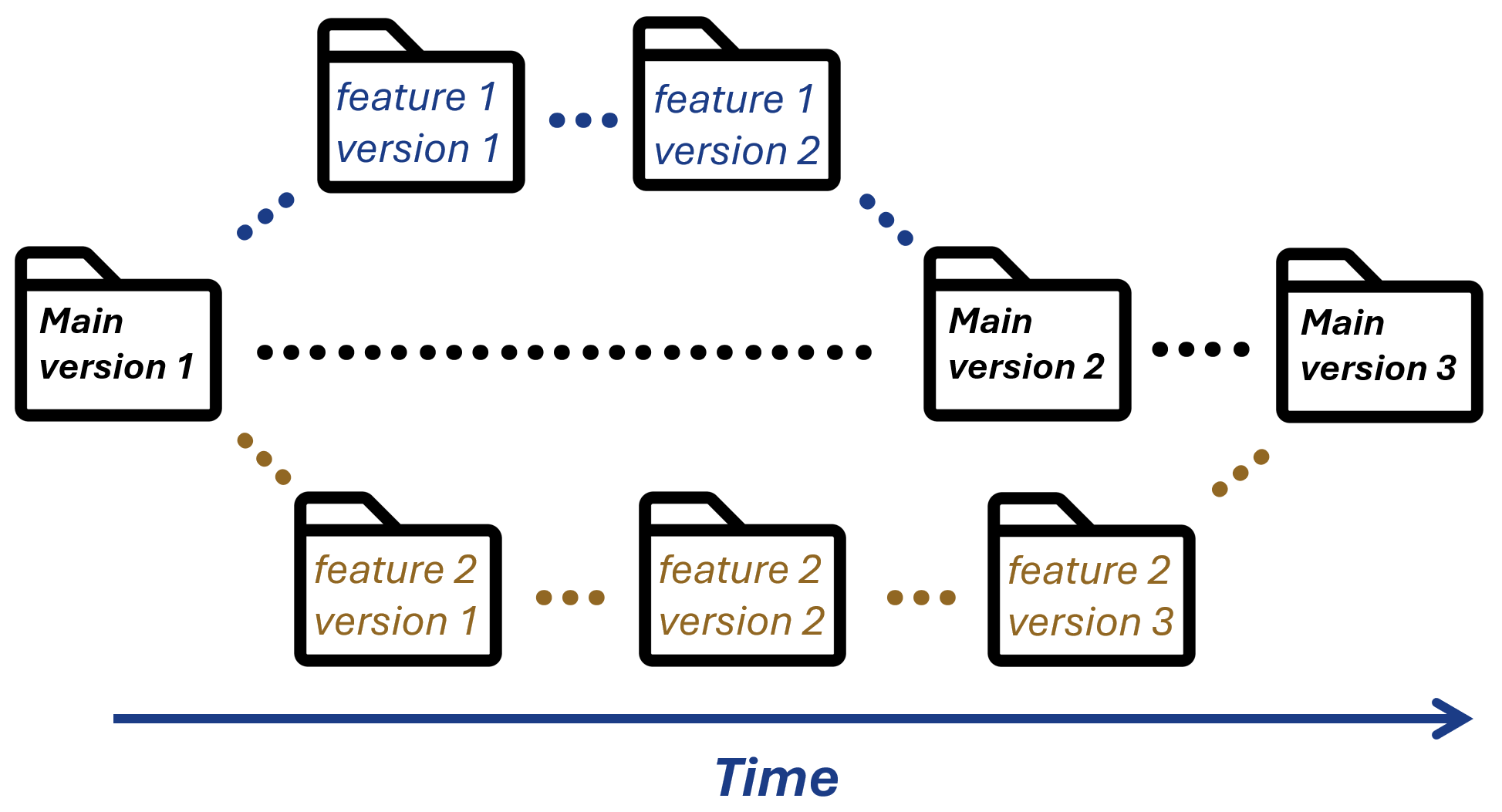
Schematic view of a project with a feature branch workflow
The corresponding basic pattern of operation is something like:
- Start from the main branch (perhaps after some period CWF development):
git checkout main. - Create a new branch for a new feature:
git checkout -b nameOfNewBranch - Work on that feature branch using a CWF
- Bring your changes back to the main branch:
git merge
I use this pattern for my open-source scientific code packages, where I want the main branch to always (hopefully!) have working code that others can use. This is one of the main benefits of a feature branch workflow: you can be developing and testing multiple items independently, and the main branch can stay clean and functional. Yes, I still sometimes commit to main when implementing a quick bugfix, but the basic pattern of “branch for a new feature, merge when it’s done” is very convenient.
I also use this pattern, as an example, for this website. I have the code that generates the website under version control, and it is configured so that every time I git push the main branch to the remote, the website gets rebuilt with the latest content. For the small updates that, e.g., appear on the welcome pages I am happy to make those changes directly on the main branch. On the other hand, when adding pages that require some period of development, testing, tinkering, and (ultimately) several commits to get right — these longer guides, or the combination css/javascript/markdown needed for the web simulations — I make a feature branch, do some development, and only merge when things are out of their “rough draft” phase.
One thing to note is that this pattern tends to favor relatively small and shorter-lived branches, since merge conflicts get more common and can be harder to resolve the longer a branch has diverged from main. Finally, I’ll note that a feature branch workflow can itself be a building block for more complex workflows. The complexity of your workflow should probably scale (logarithmically?) with the size of your project and the number of collaborators. Personally, when working on cellGPU — a code base with of order 100 files and 15000 lines of code — I never felt like something more complicated than feature branching was needed.