
How git stores a repository
I really think it helps to know even a little bit about how git stores your project and its version history. This lets you know what all of the commands in the previous guide, and it also helps you correctly reason about what will happen when you make a commit, or when you want to merge two branches. So: git is a directed acyclic graph — the nodes of this graph will be a small number of different types of “git objects”, almost all of which can then point to other git objects (forming the directed edges of the graph). We’ll see how this turns into a system for version control by meeting the important git objects.
Blobs
The most basic git object is the “blob”, which represents the contents of a file.We’ll represent them like this:

What’s going on here, and why have I written “d23a1” on the blob? When we git add a file (or when a merge changes an existing file’s content), git reads that file into a memory buffer and uses a lossless data compression algorithm to figure out what the compressed version of that file is. It then prepares a file which contains a short header followed by that compressed representation of the file; schematically it is something like:
blob [size of compressed blob in bytes]
[binary representation of compressed blob]
That is: the header has information that this is a “blob”-type object that will be of a certain size, followed by the compressed version of the file.
Finally, git calculates SHA-1 hash of the blob, and uses the 40-hexadecimal-digit representation of the hash value as the name of the blob file. The file gets stored in the .git/objects/ directory (technically git uses the first two hex digits of the hash as a subdirectory name and the remaining 38 digits as the file name). I don’t want to type 40 digits, so I’ll just use 5 letter/number combinations to represent these hash values, as in “d23a1” above.
Trees
You may have noticed that nowhere in the blob is there information about what the file is named, or where to find it relative to your project’s root directory. Perhaps you are extremely good at memorizing SHA-1 hashes, but the rest of us would probably like to go on using file names and paths as usual. The next kind of object that git uses is called a “tree” object — these are objects who’s purpose is to point to other blobs and trees, and associate the usual information that we think of when we work with files in a file system. In that sense they are like directories and subdirectories. Here’s a visual representation:
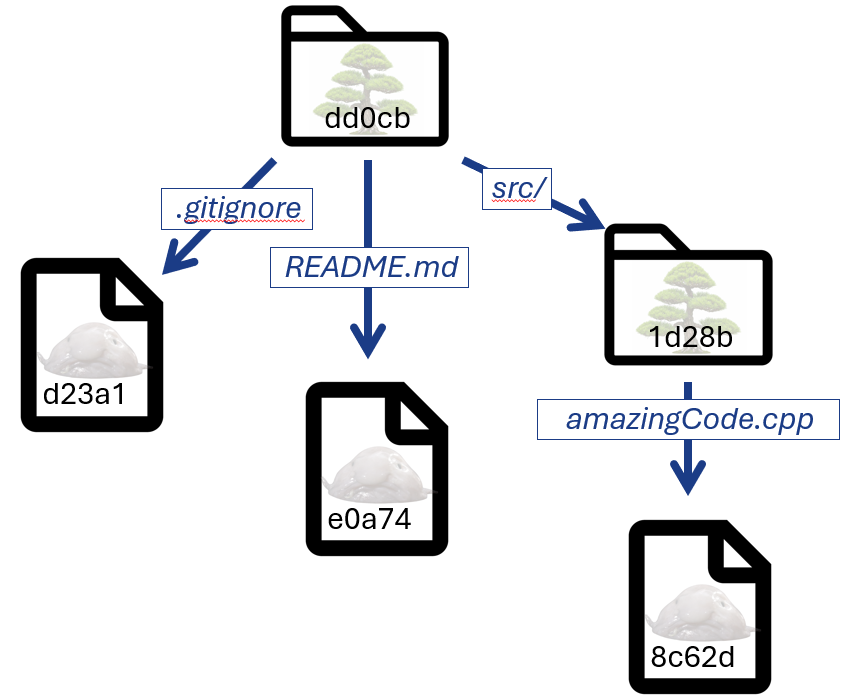
There is nothing mystical about all of these arrows pointing from trees to other objects; schematically a tree object is represented in a file as something like:
tree [size of tree in bytes]
[mode] [blob file name] [blob objectID]
[mode] [blob file name] [blob objectID]
[mode] [tree path name] [tree objectID]
...
[mode] [blob file name] [blob objectID]
That is: there is a header that has information that this is a “tree”-type object that will be of a certain size, followed by a list of things the tree points to. Each item in that list has a “mode” — is it a normal file, an executable file, a symlink, a type of directory, a git submodule — a file/path name, and finally an object ID. It’s in the sense that the header of the object contains the type and ID of other objects that a node in git’s graph “points” to another node.
Naturally, the SHA-1 hash of the tree object gets used as the tree’s object ID.
Commits
Thinking about the above, we see that we could create different versions of a project by being able to point at different tree objects — in the above image, if I could remember the dd0cb... hash I would be able to find the file corresponding to that tree, and from there get all of the sub-trees and blobs that contain information about the state of the project at that time.
Again, unless you are extremely good at memorizing SHA-1 hashes, you probably want a new type of object for this purpose. This is what a commit object is for. The format of a commit object is schematically
commit [size of commit in bytes]
tree [tree's object ID]
parent [parent commit's ID]
...
[commit information]
Yet again we have a header saying that this is a “commit”-type object of a certain size. Here that header is followed by the relevant information about the commit. This includes the tree that itself points to the blobs and trees that make up the state of the project, along with information about any “parent” commits. Typically a commit will have one parent commit, but (a) the first commit of a repository will have zero parents and (b) when merging branches a commit could have multiple parents. Finally, there is a bunch of additional information about the commit: the author, commit date, the commit message, and so on. By now, you will not be surprised to learn that a commit objects’ ID is just the SHA-1 hash of the commit object.
A sample repo over time
Bringing these three basic git object types together, let’s see what our repo looks like over the course of a few simple commits. Below I’ll go back and forth between simple commands at the shell and a visual representation of the repo. It is implied that whenever the shell command is vim [some file] I am creating or editing that file and saving it. We’ll start out simply: in a completely empty directory let’s initialize a git repo, edit a single file, then add and commit it.
$ git init
$ vim README.md
$ git add .
$ git commit -m "readme file created"
After this, here’s what our repository looks like:

Pretty simple: a single commit (with the “snapshot” represented by a drawing of a camera obscura — it’s no “blobfish for a blob”, but it’s the best I could come up with) which points at a tree, which points at a blob.
Let’s add a little bit of complexity by adding a new file in a new subdirectory of our project:
$ mkdir src
$ vim src/amazingCode.cpp
$ git add .
$ git commit -m "code added"
Now our repository looks like this:
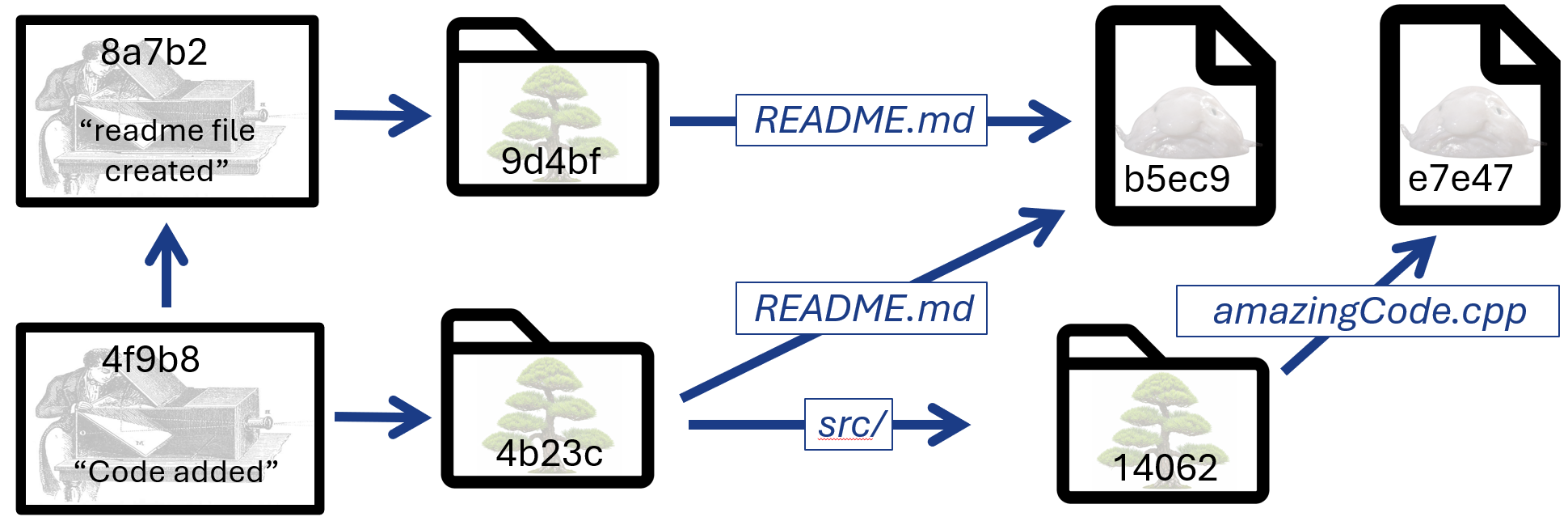
There are a few things to notice. First, as promised, the new commit points both to the parent commit and to a tree. Second, notice that git is happy to re-use any existing data it can: here, the README.md file didn’t change, so the same blob object is pointed to. On the other hand, the tree at the root of our project did change: it contains the file it already had and a new sub-tree. Thus, the new commit cannot reuse the original root tree.
To advance one step further, what if we make a new commit that (a) adds a file and (b) edits an existing file? Something like:
$ vim .gitignore
$ vim README.md
$ git add .
$ git commit -m "gitignore added and readme edited"
Based on what we know, we should expect the following. The src/ directory and its contents haven’t changed, so the new commit should point to a tree that points to the same “src/” tree as in the last illustration. The root tree that the commit points to should be different, because it needs to be a tree that points at two blobs and one tree (unlike the “one blob and one tree” root tree of the previous commit). Finally, we should see an entirely new blob appear, corresponding to the contents of the edited README.md file. Indeed, this is what we have:
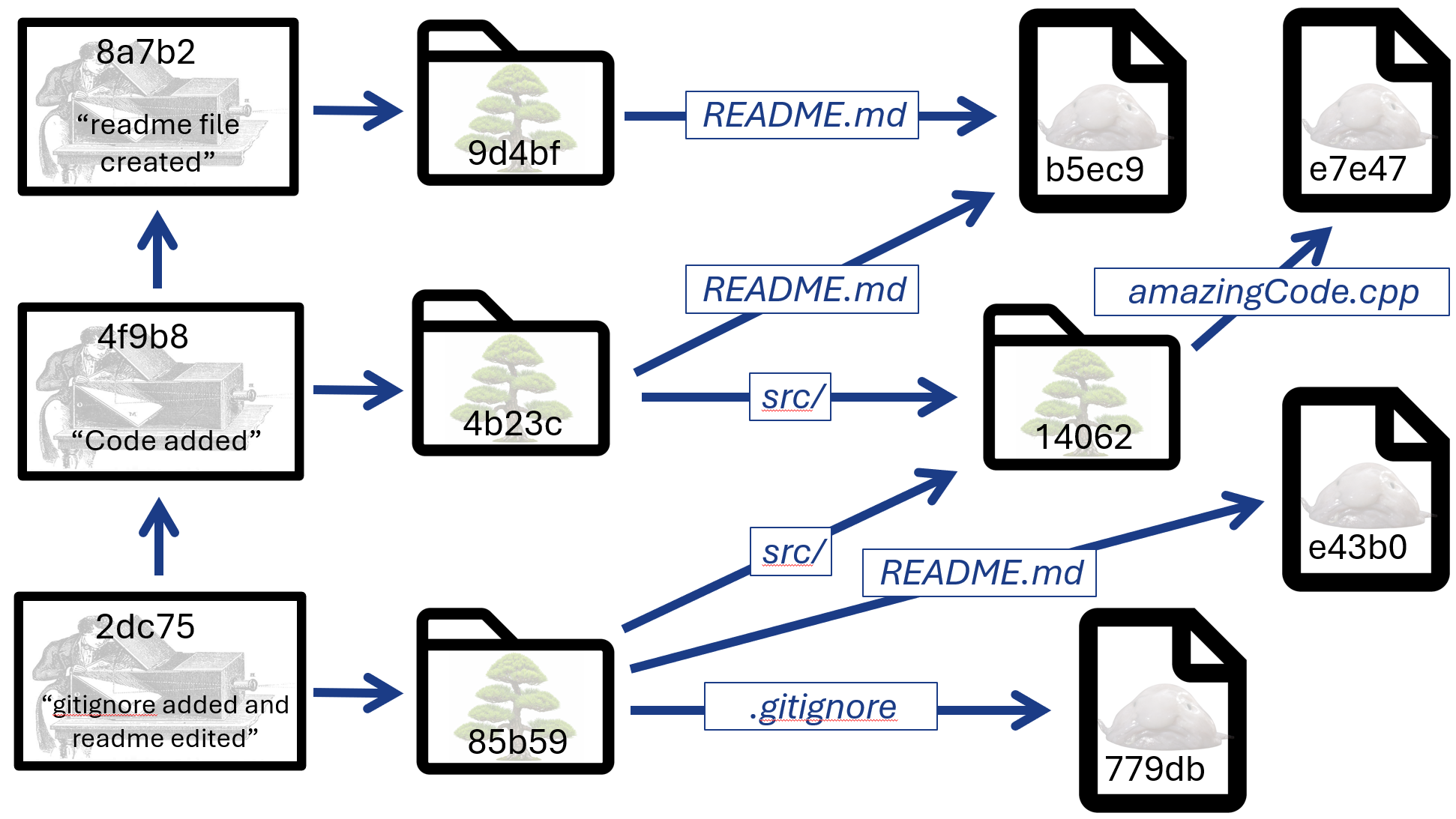
It is worth emphasizing again that there are now two different blobs corresponding to the two different versions of the README.md file in the repository. And, since both are reachable in the graph from the 2dc75 commit, you have access to both of them. Exactly as you would hope for a version control system.
References
There is one more class of git object to meet as we finish things up, and these are git references — HEADS, tags, and remotes. References act kind of like sticky notes that can tell you where you currently are in your project’s history, or point out an interesting commit (or, in fact, any interesting node in the graph), or point towards different cloud-based remote clones of your project.
First: where are you currently in your project’s history, and what commit do you want to base your next commit off of? You probably don’t want to memorize the SHA-1 hash of the answer to this (something of a recurring theme, here), so git maintains a list of HEAD references (these are files in the .git/refs/ directory, one for each branch). Each of these files just contains the SHA-1 hash of a commit object corresponding to the current working snapshot of the branch in question.
Second: you might want to have some extra mechanism for pointing at specific object in your project’s history — perhaps the commit you want to correspond to version 1.0 of a code release, or the first submission of a paper and then the finalized revision after you get the referee reports sorted out — and git provides “tags” for this purpose. Basically, a tag is just a time-stamped message that points to a specific commit. The storage format is similar to that of a commit object; technically tags can point at anything (important blobs, or important trees), but those use-cases are probably not something you need to worry about right now. I certainly don’t.
A simplified view of a remote with a few branches and a tag might look something like this:
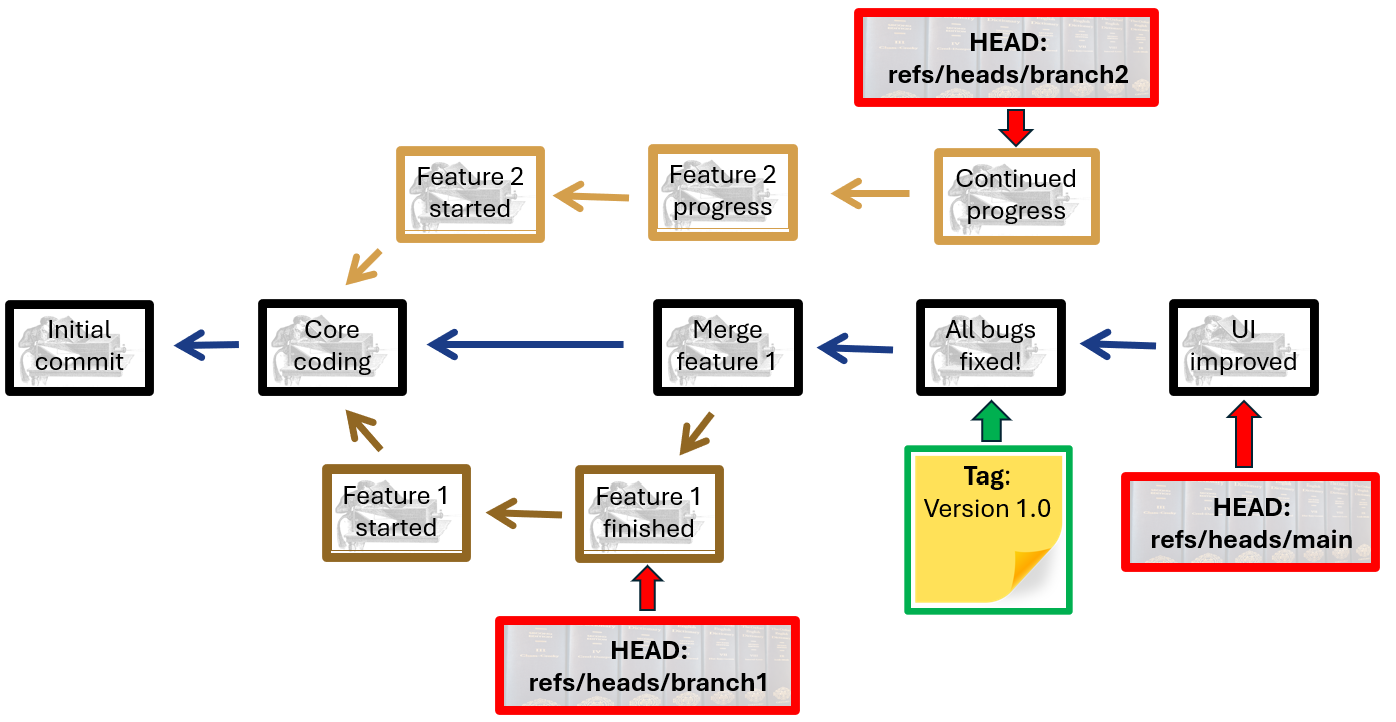
Schematic view of a project with HEADS and tags
Finally, and I suppose mostly just for completeness, there are remote references. These contain the object ID of the HEAD of the various branches on your remote(s) the last time you communicated with the remote server. You will probably not really ever need to look at these remote references (which are created in the .git/refs/remotes/ directory when you set up a remote), but if you do and you want up-to-date information, you’ll probably want to git fetch first.
Odds and ends
Git stores the contents of files in a compressed representation, and for files that have changed git will periodically do its best to represent these different versions not as totally independent blobs which are mostly the same as each other. Instead it will try to store them as a base file and a sequence of minimal changes needed to move between different versions of it (schematically, anyway… git’s model uses something called packfiles for this). The upshot is that if your repository is mostly just text files and perhaps a few images (as it might be for some code, or when writing a paper), you absolutely do not need to worry about how much space and overhead git uses to implement the model of version control described here. On the other hand, occasional changes to large files — for instance, to videos — can cause a repo to quickly grow in size. At a minimum, every file in your project that you track with git requires both the space for the file itself and for git’s compressed blob representation of it that sits in the .git/ directory. For text files this is a trivial addition, but for already-compressed video formats this might roughly double the amount of storage space you are using.
